09 Aprendizaje no supervisado: Agrupamiento#
Definiciones básicas de agrupamiento
Algoritmo de k-medias
Agrupamiento jerárquico
División
Aglomerativo
Versión v.1.0#
El notebook lo puedo modificar, esta versión es la v.1 a 04/08/2024 a las 2pm de Caracas.
Aprendizaje Automático [UCV]#
Autor: Fernando Crema García
Contacto: fernando.cremagarcia@kuleuven.be; fernando.cremagarcia@esat.kuleuven.be
Aprendizaje no supervisado#
El aprendizaje no supervisado es un tipo de algoritmo de aprendizaje automático que se utiliza para descubrir patrones en los datos. A diferencia del aprendizaje supervisado, no utiliza datos etiquetados, es decir, los datos no vienen con instrucciones predefinidas. Su objetivo es explorar la estructura de los datos para extraer información significativa sin la guía de un objetivo específico.
Si antes teníamos $\(\hat{f}(x)=y \text{ con } x\in \mathbb{R}^{n, m} \text{ y además } y \in \mathbb{R}^n \)$
Ahora simplemente disponemos de $\( x_1, x_2, \cdots x_n \text{ y solo sabemos que } x \in \mathbb{R}^m\)$
Características Principales#
Datos no etiquetados: Utiliza conjuntos de datos que no tienen etiquetas o categorías conocidas.
Descubrimiento de patrones: Identifica patrones comunes y características en los datos.
Autonomía: Capaz de operar con poca o ninguna intervención humana.
Flexibilidad: Aplicable a una amplia gama de dominios y tipos de datos.
Aplicaciones Comunes#
Agrupamiento (Clustering): Divide el conjunto de datos en grupos basados en similitudes.
Reducción de Dimensionalidad: Reduce el número de variables consideradas en un conjunto de datos.
Detección de Anomalías: Identifica casos inusuales o atípicos en los datos.
Visualización de Datos: Facilita la comprensión y visualización de estructuras complejas en los datos.
Métodos Populares#
De agrupamiento#
K-Means (k-medias): Un algoritmo de agrupamiento que asigna cada instancia de nuestros datos a uno de K grupos.
Agrupamiento jerárquico: Objetivo: construir una jerarquía de clusters. A diferencia de los métodos de agrupamiento “planos” como K-medias, el agrupamiento jerárquico no requiere especificar el número de clusters de antemano y ofrece una representación visual en forma de dendrograma que es intuitiva y reveladora.
De reducción de dimensionalidad#
Análisis de Componentes Principales (PCA): Técnica de reducción de dimensionalidad que busca una representación en menor dimensión que explique gran parte de la varianza
LLE, UMAP, t-SNE: Técnicas de reducción de dimensionalidad usadas, en la mayoría de casos, para visualizar conjuntos de datos de dimensión muy grande en imágenes o volúmenes.
Ventajas y Desventajas#
Ventajas#
Flexibilidad: Puede ser aplicado a cualquier tipo de datos.
Descubrimiento de conocimientos: Capaz de revelar estructuras ocultas en los datos.
Desventajas#
Interpretación: Los resultados pueden ser difíciles de interpretar.
Dependencia de los Datos: Requiere una gran cantidad de datos para ser efectivo.
Agrupamiento - (Clustering)#
K-medias#
Método que permite hacer una partición del dataset en \(k\) subconjuntos.
Partición de un conjunto#
Imaginemos que tenemos nuestro dataset \(D\) queremos hacer una partición del mismo y en \(k\) subconjuntos.
\(C_1 \cup C_2 \cup \cdots \cup C_K=\{1, \ldots, n\}\). Es decir, cada observación pertenece a algún cluster \(C_i\) y es claro que \(i \in [ 1, k]\).
\(C_k \cap C_{k^{\prime}}=\emptyset \; \forall \; k \neq k^{\prime}\). Es decir, no hay solapamiento de los elementos de cada cluster.
Dónde usamos particiones antes?
Variando la dimensión de \(k\)#

Tomado de ISLP P. 528
La idea principal de K-medias es que la varianza dentro de cada cluster sea la mínima posible. Esta medida, que por ahora podemos llamar, \(W(C_k)\) (within-cluster variation) nos ayuda a definir el problema a resolver:
El problema básico en k-medias#
Recordemos: qué es \(C_k\)?
La suma de todas las variaciones, por cluster, tiene que ser lo más pequeña posible.
Cuál es, entonces, el mejor \(k\) posible?
Cómo podemos definir \(W(C_k)\)#
Ideas#
Midiento distancias#
Como es el caso para regresión, SVM y redes neuronales: vamos a usar la norma 2.
Para medir la distancia entre dos instancias \(p\) y \(q\) recordemos:}
Si queremos definir la distancia entre dos puntos, es lo mismo que calcular
\begin{align} W\left(C_k\right) &= \frac{1}{\left|C_k\right|} \sum_{(i, i^{\prime}) \in C_k} d(x_i, x_{i^\prime}) \ &= \frac{1}{\left|C_k\right|} \sum_{(i, i^{\prime}) \in C_k} | x_i-x_{i^\prime}| \ &= \frac{1}{\left|C_k\right|} \sum_{(i, i^{\prime}) \in C_k} \sqrt{ \sum_{j=1}^m\left(x_{i j}-x_{i^{\prime} j}\right)^2} \end{align}
Al dividir por la cardinalidad de cada cluster \(\left|C_k\right|\) tenemos la distancia media.
Como la raíz cuadrada para números positivos es positiva y monotona creciente. Podemos eliminarla de los cálculos.
La medida de varianza dentro del clúster la definimos finalmente como:
\begin{align} W\left(C_k\right) &= \frac{1}{\left|C_k\right|} \sum_{(i, i^{\prime}) \in C_k} d(x_i, x_{i^\prime}) \ &= \frac{1}{\left|C_k\right|} \sum_{(i, i^{\prime}) \in C_k} | x_i-x_{i^\prime}|^2 \ &= \frac{1}{\left|C_k\right|} \sum_{(i, i^{\prime}) \in C_k} \sum_{j=1}^m\left(x_{i j}-x_{i^{\prime} j}\right)^2 \end{align}
Nuestro problema, finalmente, es el siguiente: $\( \underset{C_1, \ldots, C_K}{\operatorname{min}}\left\{\sum_{k=1}^k W\left(C_k\right)\right\} = \underset{C_1, \ldots, C_K}{\operatorname{min}}\left\{\sum_{k=1}^k \frac{1}{\left|C_k\right|} \sum_{(i, i^{\prime}) \in C_k} \sum_{j=1}^m\left(x_{i j}-x_{i^{\prime} j}\right)^2\right\} \)$
Es fácil demostrar que es equivalente a
Qué podemos hacer para resolver este problema?
Algoritmo de K-medias#
Asignar de manera aleatoria a \(k\) de las \(n\) instancias como “centros”. Con esto, podemos inicializar la asignación de clústers.
Iterar hasta que los clústers no cambien!:
Para cada cluster \(k\), calcula el nuevo centroide del clúster. El \(k\)-ésimo centroide es el promedio de todos los elementos del cluster \(C_k\).
Asignar de nuevo cada observación al centroide más cercano usando distancia euclideana.

INVESTIGAR#
Pero podemos escoger otro centroide?
Es fácil demostrar que el cálculo del centroide como “todos los elementos más cercanos al nuevo centroide en la iteración \(t\)” es decir, $\( \mu^{(t)}_k = \frac{1}{\left|C^{(t-1)}_k\right|} \sum_{x_i \in C^{(t-1)}_k} x_i\)$
es el mejor posible.
Cómo harían?
Código de ejemplo?#
# Import necessary libraries
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
# Example data - let's create some random data for this example
np.random.seed(0)
X = np.random.rand(100, 2)
# Specify the number of clusters (k)
k = 3
# Create and fit the model
kmeans = KMeans(n_clusters=k, random_state=0).fit(X)
# Get the cluster centers and labels
centers = kmeans.cluster_centers_
labels = kmeans.labels_
# Plotting the results
plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis')
plt.scatter(centers[:, 0], centers[:, 1], c='black', s=200, alpha=0.5)
plt.title("K-means Clustering")
plt.xlabel("X coordinate")
plt.ylabel("Y coordinate")
plt.show()
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[1], line 2
1 # Import necessary libraries
----> 2 from sklearn.cluster import KMeans
3 import matplotlib.pyplot as plt
4 import numpy as np
ModuleNotFoundError: No module named 'sklearn'
Problemas#
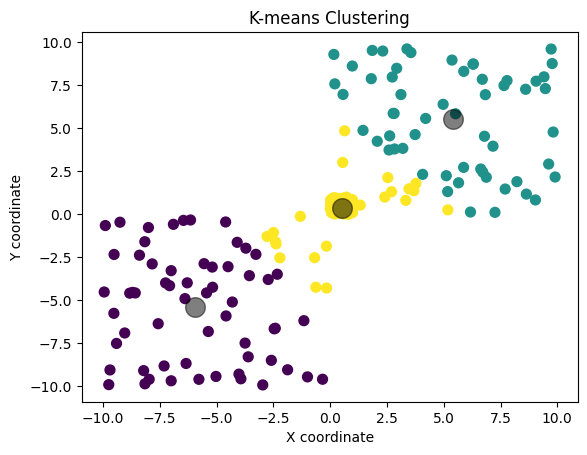
# Import necessary libraries
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
# Example data - let's create some random data for this example
np.random.seed(0)
X = np.random.rand(100, 2)
Y = 10*np.random.rand(70, 2)
Z = -10*np.random.rand(70, 2)
X = np.concatenate([X, Y, Z], axis=0)
# Specify the number of clusters (k)
k = 3
# Create and fit the model
kmeans = KMeans(n_clusters=k, random_state=0).fit(X)
# Get the cluster centers and labels
centers = kmeans.cluster_centers_
labels = kmeans.labels_
# Plotting the results
plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis')
plt.scatter(centers[:, 0], centers[:, 1], c='black', s=200, alpha=0.5)
plt.title("K-means Clustering")
plt.xlabel("X coordinate")
plt.ylabel("Y coordinate")
plt.show()
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
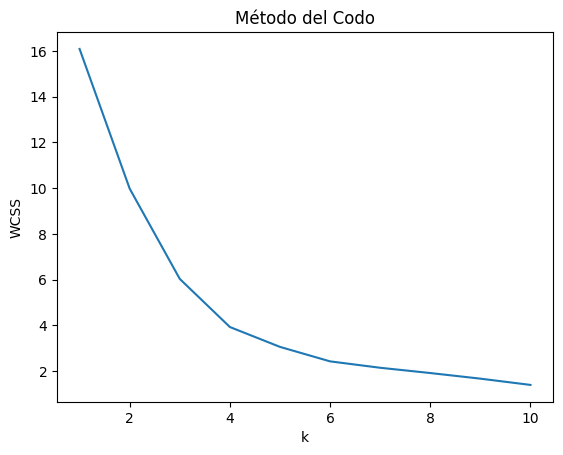
Método del Codo para K-Medias#
Escogiendo el mejor \(k\)
El método del codo es una técnica heurística utilizada para determinar el número óptimo de clusters en los que se deben agrupar los datos.
¿Cómo Funciona?#
Ejecutamos el algoritmo de K-medias en el conjunto de datos para un rango de valores de K (por ejemplo, de 1 a 10), y luego calcular la suma de los cuadrados de las distancias de cada punto a su centroide asignado.
Pasos para Implementar el Método del Codo#
Ejecutar K-medias para diferentes valores de K: Por lo general, se inicia con k=1 y se incrementa hasta un número razonable (por ejemplo, 10).
Calcular la \(W\left(C_k\right)\): Se calcula la suma total de las distancias al cuadrado entre cada punto y el centroide de su cluster.
Graficar los resultados: Se traza un gráfico de línea con los valores de K en el eje horizontal y la \(W\left(C_k\right)\) total en el eje vertical.
Identificar el ‘codo’ en el gráfico: El punto donde la disminución de \(W\left(C_k\right)\) comienza a minimizarse (es decir, el gráfico comienza a aplanarse) indica el número óptimo de clusters. Este punto se asemeja a un “codo” en el gráfico.
Importancia del Método del Codo#
El método del codo es importante porque:
Determina el Número Óptimo de Clusters: Ayuda a evitar tanto la sobre-segmentación (demasiados clusters) como la sub-segmentación (demasiados pocos clusters).
Basado en un Criterio Cuantitativo: Proporciona una métrica basada en datos para tomar una decisión informada sobre el número de clusters.
Facilidad de Implementación: Es un método relativamente sencillo y fácil de interpretar.
Limitaciones#
A pesar de su utilidad, el método del codo tiene limitaciones:
Subjetividad en la Identificación del Codo: A veces puede ser difícil identificar el punto exacto del codo, especialmente si la curva es suave.
No Funciona Bien con Algunas Distribuciones de Datos: En casos donde los datos no tienen una estructura de clústeres clara, el método del codo puede no ser efectivo.
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# Datos de ejemplo
np.random.seed(0)
X = np.random.rand(100, 2)
wcss = []
for i in range(1, 11):
kmeans = KMeans(n_clusters=i, init='k-means++', max_iter=300, n_init=10, random_state=0)
kmeans.fit(X)
wcss.append(kmeans.inertia_)
# Graficar los resultados
plt.plot(range(1, 11), wcss)
plt.title('Método del Codo')
plt.xlabel('k')
plt.ylabel('WCSS')
plt.show()
Agrupamiento Jerárquico#
El Agrupamiento Jerárquico es una técnica de aprendizaje no supervisado utilizada para construir una jerarquía de clusters. A diferencia de los métodos de agrupamiento “planos” como K-Means, el agrupamiento jerárquico no requiere especificar el número de clusters de antemano y ofrece una representación visual en forma de dendrograma que es intuitiva y reveladora.
Proceso#
Inicio: Cada punto de datos es tratado como un cluster individual.
Enlace: En cada paso, los clusters más cercanos (según algún criterio de distancia) se fusionan.
Iteración: Este proceso se repite hasta que todos los datos están en un solo cluster o hasta que se cumple un criterio de parada.
Tipos de Agrupamiento Jerárquico#
Aglomerativo (Bottom-up): Comienza con clusters individuales que se van fusionando en clusters de alto nivel.
import numpy as np
import numpy.typing as npt
def aglomerativo(D: Dataset):
Inicializar matriz de distancia M (n x n) usando D
while(criterioFin())
Cluster i, Cluster j = Escoger los mejores candidatos de clusters i y j para unirse usando M
Cluster ij = Unificar clusters i y j
Actualizar M, borrando filas i y j
Crear nueva fila en base al clúster nuevo usando criterio C para cluster ij
Modificar entradas de la matriz de distancia M
return Devolver conjunto de clusters actual;
end
Divisivo (Top down): Comienza con un cluster que contiene todos los puntos y se va dividiendo creando nuevas particiones de los datos.
def divisivo(D: Dataset, A: Algoritmo para dividir ):
Árbol T = Inicializar árbol coin raiz en dataset D
while (criterioParaDividir):
L = seleccionar hoja en árbol T basado en un criterio de selección
Actualizar árbol T, separando L en L_1 ,..., L_k
Agregar L_1 ,..., L_k como hijos de L en T
return Árbol T
Criterios de Distancia#
Enlace Simple: Minimiza la distancia entre dos clusters es igual a la distancia más corta entre dos puntos en los clusters. $\( d(A, B) \equiv \min _{\vec{x} \in A, \vec{y} \in B}\|\vec{x}-\vec{y}\| \)$
Enlace Completo: Minimiza la distancia entre dos clusters es igual a la distancia más larga entre dos puntos en los clusters. $\( d(A, B) \equiv \max _{\vec{x} \in A, \vec{y} \in B}\|\vec{x}-\vec{y}\| \)$
Enlace Promedio: Minimiza el promedio de todas las distancias entre puntos en los dos clusters.
Ward: La distancia entre dos clusters se decide en base a un criterio de varianza luego de la unión. $\( \begin{aligned} \Delta(A, B) & =\sum_{i \in A \cup B}\left\|\vec{x}_i-\vec{m}_{A \cup B}\right\|^2-\sum_{i \in A}\left\|\vec{x}_i-\vec{m}_A\right\|^2-\sum_{i \in B}\left\|\vec{x}_i-\vec{m}_B\right\|^2 \\ & =\frac{n_A n_B}{n_A+n_B}\left\|\vec{m}_A-\vec{m}_B\right\|^2 \end{aligned} \)$
Ventajas#
Visualización Intuitiva: El dendrograma proporciona una representación visual clara.
No Necesita Número de Clusters: A diferencia de otros métodos, no requiere especificar el número de clusters de antemano.
Desventajas#
Complejidad Computacional: Particularmente en grandes conjuntos de datos, puede ser computacionalmente costoso.
Sensibilidad a Ruido y Atípicos: Puede ser sensible a ruido y valores atípicos en los datos.
El agrupamiento jerárquico es especialmente útil en situaciones donde la relación entre los datos es importante y cuando se desea una representación visual detallada de cómo los grupos están relacionados entre sí.


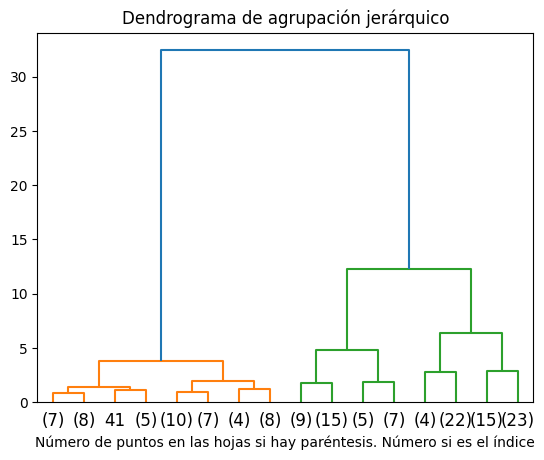
Ejemplo de cluster aglomerativo#
import numpy as np
from matplotlib import pyplot as plt
from scipy.cluster.hierarchy import dendrogram
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import load_iris
def plot_dendrogram(model, **kwargs):
# Create linkage matrix and then plot the dendrogram
# create the counts of samples under each node
counts = np.zeros(model.children_.shape[0])
n_samples = len(model.labels_)
for i, merge in enumerate(model.children_):
current_count = 0
for child_idx in merge:
if child_idx < n_samples:
current_count += 1 # leaf node
else:
current_count += counts[child_idx - n_samples]
counts[i] = current_count
linkage_matrix = np.column_stack(
[model.children_, model.distances_, counts]
).astype(float)
# Plot the corresponding dendrogram
dendrogram(linkage_matrix, **kwargs)
iris = load_iris()
X = iris.data
# setting distance_threshold=0 ensures we compute the full tree.
model = AgglomerativeClustering(distance_threshold=0, n_clusters=None)
model = model.fit(X)
plt.title("Dendrograma de agrupación jerárquico")
# plot the top three levels of the dendrogram
plot_dendrogram(model, truncate_mode="level", p=3)
plt.xlabel("Número de puntos en las hojas si hay paréntesis. Número si es el índice")
plt.show()
Alternativas#
from scipy.cluster.hierarchy import dendrogram, linkage
iris = load_iris()
X = iris.data
Z = linkage(X)
dendrogram(Z)
{'icoord': [[85.0, 85.0, 95.0, 95.0],
[145.0, 145.0, 155.0, 155.0],
[135.0, 135.0, 150.0, 150.0],
[195.0, 195.0, 205.0, 205.0],
[185.0, 185.0, 200.0, 200.0],
[225.0, 225.0, 235.0, 235.0],
[275.0, 275.0, 285.0, 285.0],
[265.0, 265.0, 280.0, 280.0],
[255.0, 255.0, 272.5, 272.5],
[245.0, 245.0, 263.75, 263.75],
[230.0, 230.0, 254.375, 254.375],
[215.0, 215.0, 242.1875, 242.1875],
[192.5, 192.5, 228.59375, 228.59375],
[305.0, 305.0, 315.0, 315.0],
[295.0, 295.0, 310.0, 310.0],
[210.546875, 210.546875, 302.5, 302.5],
[175.0, 175.0, 256.5234375, 256.5234375],
[165.0, 165.0, 215.76171875, 215.76171875],
[325.0, 325.0, 335.0, 335.0],
[365.0, 365.0, 375.0, 375.0],
[395.0, 395.0, 405.0, 405.0],
[385.0, 385.0, 400.0, 400.0],
[415.0, 415.0, 425.0, 425.0],
[392.5, 392.5, 420.0, 420.0],
[370.0, 370.0, 406.25, 406.25],
[355.0, 355.0, 388.125, 388.125],
[435.0, 435.0, 445.0, 445.0],
[371.5625, 371.5625, 440.0, 440.0],
[345.0, 345.0, 405.78125, 405.78125],
[330.0, 330.0, 375.390625, 375.390625],
[465.0, 465.0, 475.0, 475.0],
[455.0, 455.0, 470.0, 470.0],
[352.6953125, 352.6953125, 462.5, 462.5],
[190.380859375, 190.380859375, 407.59765625, 407.59765625],
[142.5, 142.5, 298.9892578125, 298.9892578125],
[125.0, 125.0, 220.74462890625, 220.74462890625],
[115.0, 115.0, 172.872314453125, 172.872314453125],
[105.0, 105.0, 143.9361572265625, 143.9361572265625],
[90.0, 90.0, 124.46807861328125, 124.46807861328125],
[485.0, 485.0, 495.0, 495.0],
[107.23403930664062, 107.23403930664062, 490.0, 490.0],
[75.0, 75.0, 298.6170196533203, 298.6170196533203],
[65.0, 65.0, 186.80850982666016, 186.80850982666016],
[55.0, 55.0, 125.90425491333008, 125.90425491333008],
[45.0, 45.0, 90.45212745666504, 90.45212745666504],
[35.0, 35.0, 67.72606372833252, 67.72606372833252],
[25.0, 25.0, 51.36303186416626, 51.36303186416626],
[15.0, 15.0, 38.18151593208313, 38.18151593208313],
[5.0, 5.0, 26.590757966041565, 26.590757966041565],
[505.0, 505.0, 515.0, 515.0],
[555.0, 555.0, 565.0, 565.0],
[545.0, 545.0, 560.0, 560.0],
[535.0, 535.0, 552.5, 552.5],
[625.0, 625.0, 635.0, 635.0],
[615.0, 615.0, 630.0, 630.0],
[645.0, 645.0, 655.0, 655.0],
[685.0, 685.0, 695.0, 695.0],
[785.0, 785.0, 795.0, 795.0],
[775.0, 775.0, 790.0, 790.0],
[765.0, 765.0, 782.5, 782.5],
[825.0, 825.0, 835.0, 835.0],
[815.0, 815.0, 830.0, 830.0],
[845.0, 845.0, 855.0, 855.0],
[822.5, 822.5, 850.0, 850.0],
[905.0, 905.0, 915.0, 915.0],
[895.0, 895.0, 910.0, 910.0],
[885.0, 885.0, 902.5, 902.5],
[875.0, 875.0, 893.75, 893.75],
[935.0, 935.0, 945.0, 945.0],
[925.0, 925.0, 940.0, 940.0],
[884.375, 884.375, 932.5, 932.5],
[865.0, 865.0, 908.4375, 908.4375],
[836.25, 836.25, 886.71875, 886.71875],
[805.0, 805.0, 861.484375, 861.484375],
[965.0, 965.0, 975.0, 975.0],
[955.0, 955.0, 970.0, 970.0],
[833.2421875, 833.2421875, 962.5, 962.5],
[773.75, 773.75, 897.87109375, 897.87109375],
[1025.0, 1025.0, 1035.0, 1035.0],
[1015.0, 1015.0, 1030.0, 1030.0],
[1045.0, 1045.0, 1055.0, 1055.0],
[1085.0, 1085.0, 1095.0, 1095.0],
[1075.0, 1075.0, 1090.0, 1090.0],
[1065.0, 1065.0, 1082.5, 1082.5],
[1050.0, 1050.0, 1073.75, 1073.75],
[1105.0, 1105.0, 1115.0, 1115.0],
[1061.875, 1061.875, 1110.0, 1110.0],
[1022.5, 1022.5, 1085.9375, 1085.9375],
[1005.0, 1005.0, 1054.21875, 1054.21875],
[995.0, 995.0, 1029.609375, 1029.609375],
[985.0, 985.0, 1012.3046875, 1012.3046875],
[835.810546875, 835.810546875, 998.65234375, 998.65234375],
[755.0, 755.0, 917.2314453125, 917.2314453125],
[745.0, 745.0, 836.11572265625, 836.11572265625],
[735.0, 735.0, 790.557861328125, 790.557861328125],
[1145.0, 1145.0, 1155.0, 1155.0],
[1135.0, 1135.0, 1150.0, 1150.0],
[1175.0, 1175.0, 1185.0, 1185.0],
[1165.0, 1165.0, 1180.0, 1180.0],
[1142.5, 1142.5, 1172.5, 1172.5],
[1125.0, 1125.0, 1157.5, 1157.5],
[1215.0, 1215.0, 1225.0, 1225.0],
[1205.0, 1205.0, 1220.0, 1220.0],
[1195.0, 1195.0, 1212.5, 1212.5],
[1141.25, 1141.25, 1203.75, 1203.75],
[1245.0, 1245.0, 1255.0, 1255.0],
[1235.0, 1235.0, 1250.0, 1250.0],
[1172.5, 1172.5, 1242.5, 1242.5],
[1275.0, 1275.0, 1285.0, 1285.0],
[1265.0, 1265.0, 1280.0, 1280.0],
[1295.0, 1295.0, 1305.0, 1305.0],
[1325.0, 1325.0, 1335.0, 1335.0],
[1345.0, 1345.0, 1355.0, 1355.0],
[1330.0, 1330.0, 1350.0, 1350.0],
[1315.0, 1315.0, 1340.0, 1340.0],
[1300.0, 1300.0, 1327.5, 1327.5],
[1365.0, 1365.0, 1375.0, 1375.0],
[1395.0, 1395.0, 1405.0, 1405.0],
[1385.0, 1385.0, 1400.0, 1400.0],
[1425.0, 1425.0, 1435.0, 1435.0],
[1415.0, 1415.0, 1430.0, 1430.0],
[1392.5, 1392.5, 1422.5, 1422.5],
[1455.0, 1455.0, 1465.0, 1465.0],
[1445.0, 1445.0, 1460.0, 1460.0],
[1407.5, 1407.5, 1452.5, 1452.5],
[1370.0, 1370.0, 1430.0, 1430.0],
[1313.75, 1313.75, 1400.0, 1400.0],
[1272.5, 1272.5, 1356.875, 1356.875],
[1207.5, 1207.5, 1314.6875, 1314.6875],
[1485.0, 1485.0, 1495.0, 1495.0],
[1475.0, 1475.0, 1490.0, 1490.0],
[1261.09375, 1261.09375, 1482.5, 1482.5],
[762.7789306640625, 762.7789306640625, 1371.796875, 1371.796875],
[725.0, 725.0, 1067.2879028320312, 1067.2879028320312],
[715.0, 715.0, 896.1439514160156, 896.1439514160156],
[705.0, 705.0, 805.5719757080078, 805.5719757080078],
[690.0, 690.0, 755.2859878540039, 755.2859878540039],
[675.0, 675.0, 722.642993927002, 722.642993927002],
[665.0, 665.0, 698.821496963501, 698.821496963501],
[650.0, 650.0, 681.9107484817505, 681.9107484817505],
[622.5, 622.5, 665.9553742408752, 665.9553742408752],
[605.0, 605.0, 644.2276871204376, 644.2276871204376],
[595.0, 595.0, 624.6138435602188, 624.6138435602188],
[585.0, 585.0, 609.8069217801094, 609.8069217801094],
[575.0, 575.0, 597.4034608900547, 597.4034608900547],
[543.75, 543.75, 586.2017304450274, 586.2017304450274],
[525.0, 525.0, 564.9758652225137, 564.9758652225137],
[510.0, 510.0, 544.9879326112568, 544.9879326112568],
[15.795378983020782,
15.795378983020782,
527.4939663056284,
527.4939663056284]],
'dcoord': [[0.0, 0.282842712474619, 0.282842712474619, 0.0],
[0.0, 0.14142135623730928, 0.14142135623730928, 0.0],
[0.0, 0.14142135623730953, 0.14142135623730953, 0.14142135623730928],
[0.0, 0.14142135623730964, 0.14142135623730964, 0.0],
[0.0, 0.14142135623730978, 0.14142135623730978, 0.14142135623730964],
[0.0, 0.1414213562373093, 0.1414213562373093, 0.0],
[0.0, 0.1, 0.1, 0.0],
[0.0, 0.14142135623730964, 0.14142135623730964, 0.1],
[0.0, 0.14142135623730986, 0.14142135623730986, 0.14142135623730964],
[0.0, 0.1414213562373099, 0.1414213562373099, 0.14142135623730986],
[0.1414213562373093,
0.14142135623730995,
0.14142135623730995,
0.1414213562373099],
[0.0, 0.17320508075688762, 0.17320508075688762, 0.14142135623730995],
[0.14142135623730978,
0.17320508075688812,
0.17320508075688812,
0.17320508075688762],
[0.0, 0.14142135623730948, 0.14142135623730948, 0.0],
[0.0, 0.20000000000000018, 0.20000000000000018, 0.14142135623730948],
[0.17320508075688812,
0.22360679774997827,
0.22360679774997827,
0.20000000000000018],
[0.0, 0.22360679774997858, 0.22360679774997858, 0.22360679774997827],
[0.0, 0.22360679774997871, 0.22360679774997871, 0.22360679774997858],
[0.0, 0.10000000000000053, 0.10000000000000053, 0.0],
[0.0, 0.09999999999999964, 0.09999999999999964, 0.0],
[0.0, 0.09999999999999998, 0.09999999999999998, 0.0],
[0.0, 0.14142135623730917, 0.14142135623730917, 0.09999999999999998],
[0.0, 0.14142135623730925, 0.14142135623730925, 0.0],
[0.14142135623730917,
0.1414213562373093,
0.1414213562373093,
0.14142135623730925],
[0.09999999999999964,
0.14142135623730964,
0.14142135623730964,
0.1414213562373093],
[0.0, 0.14142135623730964, 0.14142135623730964, 0.14142135623730964],
[0.0, 0.14142135623730964, 0.14142135623730964, 0.0],
[0.14142135623730964,
0.14142135623730995,
0.14142135623730995,
0.14142135623730964],
[0.0, 0.22360679774997877, 0.22360679774997877, 0.14142135623730995],
[0.10000000000000053,
0.22360679774997896,
0.22360679774997896,
0.22360679774997877],
[0.0, 0.1999999999999998, 0.1999999999999998, 0.0],
[0.0, 0.22360679774997896, 0.22360679774997896, 0.1999999999999998],
[0.22360679774997896,
0.22360679774997902,
0.22360679774997902,
0.22360679774997896],
[0.22360679774997871,
0.22360679774997916,
0.22360679774997916,
0.22360679774997902],
[0.14142135623730953,
0.2449489742783178,
0.2449489742783178,
0.22360679774997916],
[0.0, 0.244948974278318, 0.244948974278318, 0.2449489742783178],
[0.0, 0.2999999999999998, 0.2999999999999998, 0.244948974278318],
[0.0, 0.3, 0.3, 0.2999999999999998],
[0.282842712474619, 0.3000000000000001, 0.3000000000000001, 0.3],
[0.0, 0.33166247903553986, 0.33166247903553986, 0.0],
[0.3000000000000001,
0.3464101615137753,
0.3464101615137753,
0.33166247903553986],
[0.0, 0.3464101615137753, 0.3464101615137753, 0.3464101615137753],
[0.0, 0.3464101615137755, 0.3464101615137755, 0.3464101615137753],
[0.0, 0.3464101615137755, 0.3464101615137755, 0.3464101615137755],
[0.0, 0.3605551275463988, 0.3605551275463988, 0.3464101615137755],
[0.0, 0.3605551275463992, 0.3605551275463992, 0.3605551275463988],
[0.0, 0.412310562561766, 0.412310562561766, 0.3605551275463992],
[0.0, 0.45825756949558394, 0.45825756949558394, 0.412310562561766],
[0.0, 0.6244997998398398, 0.6244997998398398, 0.45825756949558394],
[0.0, 0.4123105625617661, 0.4123105625617661, 0.0],
[0.0, 0.1414213562373093, 0.1414213562373093, 0.0],
[0.0, 0.3605551275463989, 0.3605551275463989, 0.1414213562373093],
[0.0, 0.3872983346207412, 0.3872983346207412, 0.3605551275463989],
[0.0, 0.26457513110645964, 0.26457513110645964, 0.0],
[0.0, 0.4123105625617659, 0.4123105625617659, 0.26457513110645964],
[0.0, 0.26457513110645864, 0.26457513110645864, 0.0],
[0.0, 0.26457513110645936, 0.26457513110645936, 0.0],
[0.0, 0.14142135623730995, 0.14142135623730995, 0.0],
[0.0, 0.19999999999999973, 0.19999999999999973, 0.14142135623730995],
[0.0, 0.22360679774997896, 0.22360679774997896, 0.19999999999999973],
[0.0, 0.1414213562373093, 0.1414213562373093, 0.0],
[0.0, 0.17320508075688762, 0.17320508075688762, 0.1414213562373093],
[0.0, 0.20000000000000018, 0.20000000000000018, 0.0],
[0.17320508075688762,
0.24494897427831766,
0.24494897427831766,
0.20000000000000018],
[0.0, 0.14142135623730964, 0.14142135623730964, 0.0],
[0.0, 0.14142135623730995, 0.14142135623730995, 0.14142135623730964],
[0.0, 0.17320508075688815, 0.17320508075688815, 0.14142135623730995],
[0.0, 0.1732050807568884, 0.1732050807568884, 0.17320508075688815],
[0.0, 0.14142135623730964, 0.14142135623730964, 0.0],
[0.0, 0.24494897427831766, 0.24494897427831766, 0.14142135623730964],
[0.1732050807568884,
0.26457513110645864,
0.26457513110645864,
0.24494897427831766],
[0.0, 0.26457513110645914, 0.26457513110645914, 0.26457513110645864],
[0.24494897427831766,
0.2645751311064592,
0.2645751311064592,
0.26457513110645914],
[0.0, 0.3000000000000001, 0.3000000000000001, 0.2645751311064592],
[0.0, 0.1999999999999993, 0.1999999999999993, 0.0],
[0.0, 0.30000000000000027, 0.30000000000000027, 0.1999999999999993],
[0.3000000000000001,
0.3162277660168378,
0.3162277660168378,
0.30000000000000027],
[0.22360679774997896,
0.33166247903553975,
0.33166247903553975,
0.3162277660168378],
[0.0, 0.26457513110645914, 0.26457513110645914, 0.0],
[0.0, 0.2828427124746193, 0.2828427124746193, 0.26457513110645914],
[0.0, 0.20000000000000018, 0.20000000000000018, 0.0],
[0.0, 0.14142135623730995, 0.14142135623730995, 0.0],
[0.0, 0.24494897427831722, 0.24494897427831722, 0.14142135623730995],
[0.0, 0.24494897427831766, 0.24494897427831766, 0.24494897427831722],
[0.20000000000000018,
0.2645751311064587,
0.2645751311064587,
0.24494897427831766],
[0.0, 0.2645751311064593, 0.2645751311064593, 0.0],
[0.2645751311064587,
0.31622776601683755,
0.31622776601683755,
0.2645751311064593],
[0.2828427124746193,
0.31622776601683783,
0.31622776601683783,
0.31622776601683755],
[0.0, 0.31622776601683794, 0.31622776601683794, 0.31622776601683783],
[0.0, 0.31622776601683816, 0.31622776601683816, 0.31622776601683794],
[0.0, 0.33166247903554, 0.33166247903554, 0.31622776601683816],
[0.33166247903553975,
0.3464101615137753,
0.3464101615137753,
0.33166247903554],
[0.0, 0.3464101615137758, 0.3464101615137758, 0.3464101615137753],
[0.0, 0.3741657386773941, 0.3741657386773941, 0.3464101615137758],
[0.0, 0.38729833462074165, 0.38729833462074165, 0.3741657386773941],
[0.0, 0.14142135623730964, 0.14142135623730964, 0.0],
[0.0, 0.22360679774997896, 0.22360679774997896, 0.14142135623730964],
[0.0, 0.17320508075688762, 0.17320508075688762, 0.0],
[0.0, 0.24494897427831777, 0.24494897427831777, 0.17320508075688762],
[0.22360679774997896,
0.24494897427831838,
0.24494897427831838,
0.24494897427831777],
[0.0, 0.282842712474618, 0.282842712474618, 0.24494897427831838],
[0.0, 0.0, 0.0, 0.0],
[0.0, 0.26457513110645897, 0.26457513110645897, 0.0],
[0.0, 0.31622776601683755, 0.31622776601683755, 0.26457513110645897],
[0.282842712474618,
0.33166247903553997,
0.33166247903553997,
0.31622776601683755],
[0.0, 0.33166247903553975, 0.33166247903553975, 0.0],
[0.0, 0.3605551275463984, 0.3605551275463984, 0.33166247903553975],
[0.33166247903553997,
0.3605551275463989,
0.3605551275463989,
0.3605551275463984],
[0.0, 0.2449489742783171, 0.2449489742783171, 0.0],
[0.0, 0.3000000000000001, 0.3000000000000001, 0.2449489742783171],
[0.0, 0.17320508075688787, 0.17320508075688787, 0.0],
[0.0, 0.22360679774997935, 0.22360679774997935, 0.0],
[0.0, 0.24494897427831785, 0.24494897427831785, 0.0],
[0.22360679774997935,
0.26457513110645947,
0.26457513110645947,
0.24494897427831785],
[0.0, 0.2999999999999998, 0.2999999999999998, 0.26457513110645947],
[0.17320508075688787,
0.34641016151377513,
0.34641016151377513,
0.2999999999999998],
[0.0, 0.24494897427831822, 0.24494897427831822, 0.0],
[0.0, 0.1414213562373093, 0.1414213562373093, 0.0],
[0.0, 0.24494897427831783, 0.24494897427831783, 0.1414213562373093],
[0.0, 0.10000000000000009, 0.10000000000000009, 0.0],
[0.0, 0.30000000000000016, 0.30000000000000016, 0.10000000000000009],
[0.24494897427831783,
0.3316624790355402,
0.3316624790355402,
0.30000000000000016],
[0.0, 0.22360679774997935, 0.22360679774997935, 0.0],
[0.0, 0.34641016151377513, 0.34641016151377513, 0.22360679774997935],
[0.3316624790355402,
0.3605551275463988,
0.3605551275463988,
0.34641016151377513],
[0.24494897427831822,
0.3605551275463989,
0.3605551275463989,
0.3605551275463988],
[0.34641016151377513,
0.360555127546399,
0.360555127546399,
0.3605551275463989],
[0.3000000000000001,
0.374165738677394,
0.374165738677394,
0.360555127546399],
[0.3605551275463989,
0.3741657386773942,
0.3741657386773942,
0.374165738677394],
[0.0, 0.3464101615137756, 0.3464101615137756, 0.0],
[0.0, 0.38729833462074187, 0.38729833462074187, 0.3464101615137756],
[0.3741657386773942,
0.3999999999999997,
0.3999999999999997,
0.38729833462074187],
[0.38729833462074165,
0.41231056256176624,
0.41231056256176624,
0.3999999999999997],
[0.0, 0.4242640687119284, 0.4242640687119284, 0.41231056256176624],
[0.0, 0.42426406871192884, 0.42426406871192884, 0.4242640687119284],
[0.0, 0.43588989435406705, 0.43588989435406705, 0.42426406871192884],
[0.26457513110645936,
0.43588989435406733,
0.43588989435406733,
0.43588989435406705],
[0.0, 0.4898979485566353, 0.4898979485566353, 0.43588989435406733],
[0.0, 0.4898979485566356, 0.4898979485566356, 0.4898979485566353],
[0.26457513110645864,
0.5099019513592786,
0.5099019513592786,
0.4898979485566356],
[0.4123105625617659,
0.5291502622129179,
0.5291502622129179,
0.5099019513592786],
[0.0, 0.5385164807134504, 0.5385164807134504, 0.5291502622129179],
[0.0, 0.5385164807134505, 0.5385164807134505, 0.5385164807134504],
[0.0, 0.5567764362830021, 0.5567764362830021, 0.5385164807134505],
[0.0, 0.6324555320336759, 0.6324555320336759, 0.5567764362830021],
[0.3872983346207412,
0.6480740698407862,
0.6480740698407862,
0.6324555320336759],
[0.0, 0.7348469228349535, 0.7348469228349535, 0.6480740698407862],
[0.4123105625617661,
0.818535277187245,
0.818535277187245,
0.7348469228349535],
[0.6244997998398398,
1.6401219466856727,
1.6401219466856727,
0.818535277187245]],
'ivl': ['41',
'22',
'14',
'15',
'44',
'33',
'32',
'16',
'20',
'31',
'36',
'24',
'13',
'46',
'19',
'21',
'6',
'11',
'2',
'3',
'47',
'25',
'29',
'30',
'12',
'45',
'1',
'9',
'34',
'42',
'8',
'38',
'10',
'48',
'35',
'49',
'7',
'39',
'40',
'0',
'17',
'4',
'37',
'27',
'28',
'43',
'23',
'26',
'5',
'18',
'117',
'131',
'106',
'98',
'60',
'57',
'93',
'109',
'108',
'134',
'135',
'118',
'105',
'122',
'68',
'87',
'62',
'114',
'107',
'130',
'119',
'100',
'64',
'59',
'85',
'79',
'73',
'78',
'63',
'91',
'61',
'69',
'80',
'81',
'53',
'89',
'90',
'88',
'94',
'99',
'95',
'96',
'67',
'82',
'92',
'55',
'66',
'84',
'71',
'76',
'77',
'86',
'50',
'52',
'74',
'97',
'54',
'58',
'65',
'75',
'51',
'56',
'149',
'70',
'127',
'138',
'146',
'123',
'126',
'121',
'113',
'101',
'142',
'72',
'83',
'133',
'115',
'136',
'148',
'112',
'139',
'124',
'120',
'143',
'140',
'144',
'141',
'145',
'103',
'116',
'137',
'104',
'128',
'132',
'111',
'110',
'147',
'102',
'125',
'129'],
'leaves': [41,
22,
14,
15,
44,
33,
32,
16,
20,
31,
36,
24,
13,
46,
19,
21,
6,
11,
2,
3,
47,
25,
29,
30,
12,
45,
1,
9,
34,
42,
8,
38,
10,
48,
35,
49,
7,
39,
40,
0,
17,
4,
37,
27,
28,
43,
23,
26,
5,
18,
117,
131,
106,
98,
60,
57,
93,
109,
108,
134,
135,
118,
105,
122,
68,
87,
62,
114,
107,
130,
119,
100,
64,
59,
85,
79,
73,
78,
63,
91,
61,
69,
80,
81,
53,
89,
90,
88,
94,
99,
95,
96,
67,
82,
92,
55,
66,
84,
71,
76,
77,
86,
50,
52,
74,
97,
54,
58,
65,
75,
51,
56,
149,
70,
127,
138,
146,
123,
126,
121,
113,
101,
142,
72,
83,
133,
115,
136,
148,
112,
139,
124,
120,
143,
140,
144,
141,
145,
103,
116,
137,
104,
128,
132,
111,
110,
147,
102,
125,
129],
'color_list': ['C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C0'],
'leaves_color_list': ['C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C1',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2',
'C2']}
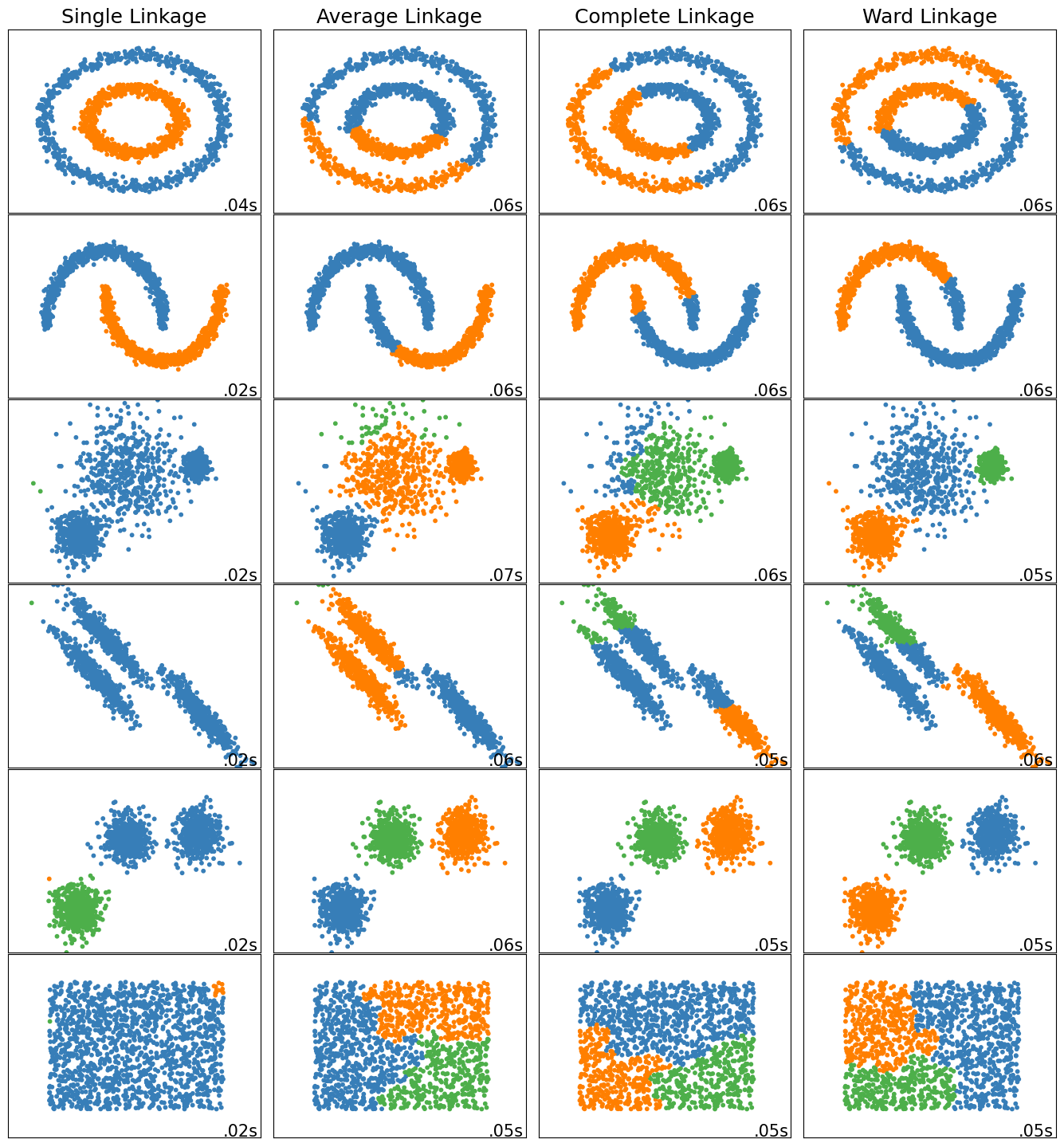
Comparando las distancias#
Ejemplo de Comparando métodos de cluster aglomerativo
import time
import warnings
from itertools import cycle, islice
import matplotlib.pyplot as plt
import numpy as np
from sklearn import cluster, datasets
from sklearn.preprocessing import StandardScaler
n_samples = 1500
noisy_circles = datasets.make_circles(
n_samples=n_samples, factor=0.5, noise=0.05, random_state=170
)
noisy_moons = datasets.make_moons(n_samples=n_samples, noise=0.05, random_state=170)
blobs = datasets.make_blobs(n_samples=n_samples, random_state=170)
rng = np.random.RandomState(170)
no_structure = rng.rand(n_samples, 2), None
# Anisotropicly distributed data
X, y = datasets.make_blobs(n_samples=n_samples, random_state=170)
transformation = [[0.6, -0.6], [-0.4, 0.8]]
X_aniso = np.dot(X, transformation)
aniso = (X_aniso, y)
# blobs with varied variances
varied = datasets.make_blobs(
n_samples=n_samples, cluster_std=[1.0, 2.5, 0.5], random_state=170
)
# Set up cluster parameters
plt.figure(figsize=(9 * 1.3 + 2, 14.5))
plt.subplots_adjust(
left=0.02, right=0.98, bottom=0.001, top=0.96, wspace=0.05, hspace=0.01
)
plot_num = 1
default_base = {"n_neighbors": 10, "n_clusters": 3}
datasets = [
(noisy_circles, {"n_clusters": 2}),
(noisy_moons, {"n_clusters": 2}),
(varied, {"n_neighbors": 2}),
(aniso, {"n_neighbors": 2}),
(blobs, {}),
(no_structure, {}),
]
for i_dataset, (dataset, algo_params) in enumerate(datasets):
# update parameters with dataset-specific values
params = default_base.copy()
params.update(algo_params)
X, y = dataset
# normalize dataset for easier parameter selection
X = StandardScaler().fit_transform(X)
# ============
# Create cluster objects
# ============
ward = cluster.AgglomerativeClustering(
n_clusters=params["n_clusters"], linkage="ward"
)
complete = cluster.AgglomerativeClustering(
n_clusters=params["n_clusters"], linkage="complete"
)
average = cluster.AgglomerativeClustering(
n_clusters=params["n_clusters"], linkage="average"
)
single = cluster.AgglomerativeClustering(
n_clusters=params["n_clusters"], linkage="single"
)
clustering_algorithms = (
("Enlace simple", single),
("Enlace promedio", average),
("Enlace completo", complete),
("Enlace ward", ward),
)
for name, algorithm in clustering_algorithms:
t0 = time.time()
# catch warnings related to kneighbors_graph
with warnings.catch_warnings():
warnings.filterwarnings(
"ignore",
message="the number of connected components of the "
+ "connectivity matrix is [0-9]{1,2}"
+ " > 1. Completing it to avoid stopping the tree early.",
category=UserWarning,
)
algorithm.fit(X)
t1 = time.time()
if hasattr(algorithm, "labels_"):
y_pred = algorithm.labels_.astype(int)
else:
y_pred = algorithm.predict(X)
plt.subplot(len(datasets), len(clustering_algorithms), plot_num)
if i_dataset == 0:
plt.title(name, size=18)
colors = np.array(
list(
islice(
cycle(
[
"#377eb8",
"#ff7f00",
"#4daf4a",
"#f781bf",
"#a65628",
"#984ea3",
"#999999",
"#e41a1c",
"#dede00",
]
),
int(max(y_pred) + 1),
)
)
)
plt.scatter(X[:, 0], X[:, 1], s=10, color=colors[y_pred])
plt.xlim(-2.5, 2.5)
plt.ylim(-2.5, 2.5)
plt.xticks(())
plt.yticks(())
plt.text(
0.99,
0.01,
("%.2fs" % (t1 - t0)).lstrip("0"),
transform=plt.gca().transAxes,
size=15,
horizontalalignment="right",
)
plot_num += 1
plt.show()
Divisivo: K-medias bisector#
El algoritmo de bisección de k-medias es un algoritmo de agrupamiento jerárquico de arriba hacia abajo en el que cada nodo se divide en exactamente dos hijos con un algoritmo de 2 medias.